Waveform Solver Input File Generator
An API to generate input files for many different seismic waveform solvers.
This project is maintained by krischer
Waveform Solver Input File Generator
Seismic waveform solvers are generally written in a high-performance language and are controlled with the help of carefully crafted input files. These input files are very solver dependent and have their own quirks. The present module attempts to create a generic input file generator that hides the actual input files' syntax and has a usable Python API.
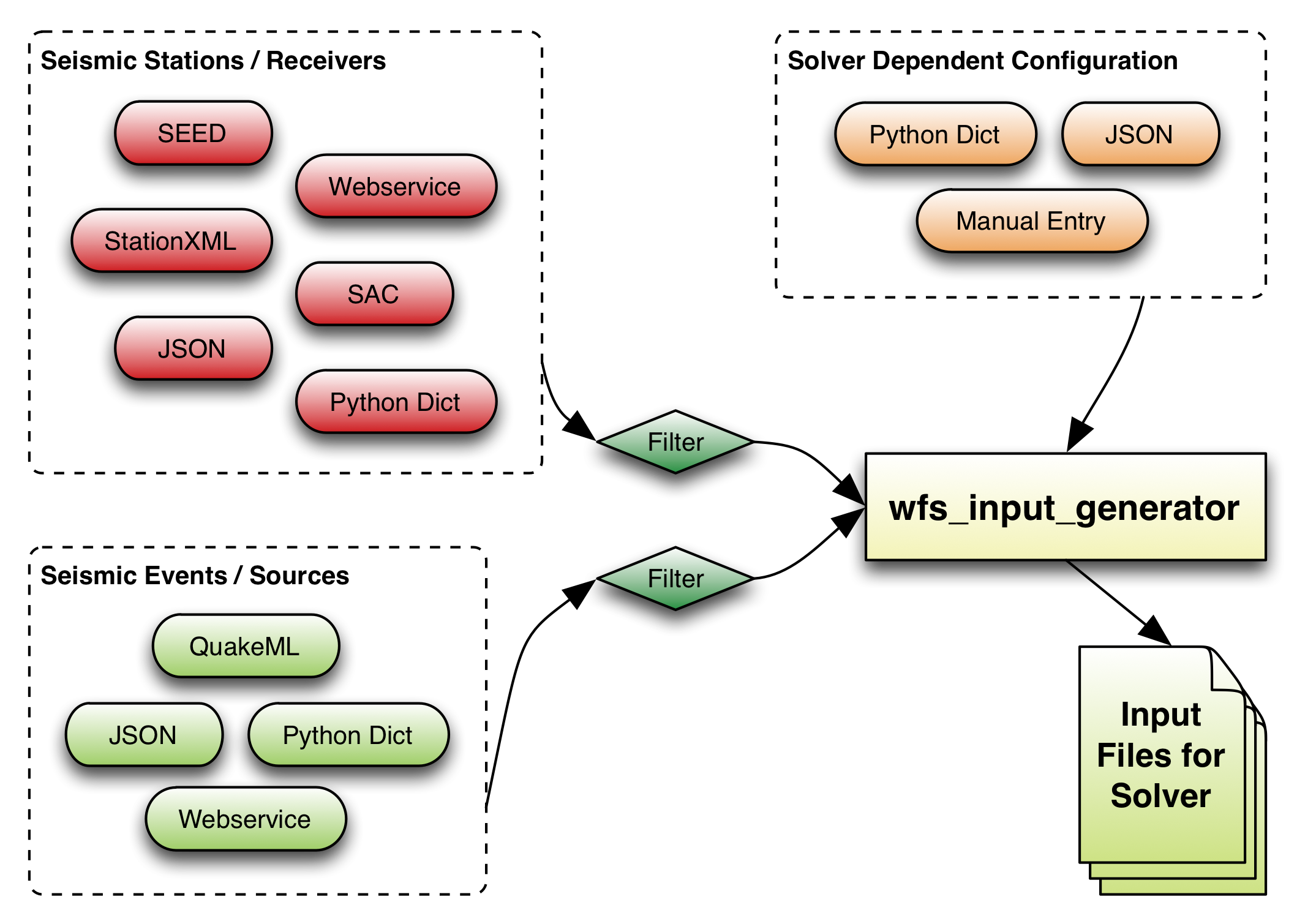
From a high-level point of view the solvers require three distinct types of input: the sources, the receivers, and a detailed configuration of the solver which includes all the remaining parts like time-stepping, the domain setup, which type of simulation to perform, and many more.
The wfs_input_generator module is able to extract the list of sources (or
seimic events) and the list of receivers (or seismic stations) from
various common formats that are readily available. It also helps with the
solver specific configuration, other then the input file formatting, by
dividing the configuration values in a (hopefully) small set of required
parameters and a larger list of optional ones with sensible default values.
Furthermore it takes care of a lot of sanity, type, and availability checks
with the goal of producing only valid input files.
A main focus of the development was to make it as easy as possible to add support for further waveform solver input file formats. This is achieved by employing a system of simple backends; one for each supported solver.
The following sketch shows a short overview of the module's workings:
Navigation
Dependencies and Installation
The module is written in pure Python and thus only has very minimal dependencies. It currently only works with Python 2.7.x as ObsPy does not yet support Python 3.x.
Requirements
- Python 2.7.x
- ObsPy >= 0.8.3
Additional requirements for running the test suite:
- pytest
- flake8 >= 2.0
- mock
Installation
User Installation
To install the most recent version, make sure ObsPy is installed and execute
$ pip install https://github.com/krischer/wfs_input_generator/archive/master.zip
To also install the requirements for the tests, run
$ pip install https://github.com/krischer/wfs_input_generator/archive/master.zip[tests]
Developer Installation
If you want to develop your own backends for writing input files for new solvers you have to install the wfs_input_generator with an in-place installation.
$ git clone https://github.com/krischer/wfs_input_generator.git
$ cd wfs_input_generator
$ pip install -v -e .[tests]
Running the Tests
The simplest way to launch the tests is to use the py.test command in the
main wfs_input_generator directory. It will take care of discovering and
executing all tests.
$ cd wfs_input_generator
$ py.test
Test session starts (darwin, 2.7.5)
...
If you intend on developing for this module, please write tests for your additions and also guard against regressions by ensuring the existing test suite passes.
Usage
The input file generation is steered with a Python script.
The first step it to create an InputFileGenerator object.
from wfs_input_generator import InputFileGenerator
gen = InputFileGenerator()
This object requires seismic events, which act as the sources, seismic stations, which act as the receivers and finally some solver specific configuration to be able to eventually generate input files for different solvers.
The events and stations can be the same for every solver, but the rest of the configuration cannot be unified; the different solvers simply require very different parameters.
Adding Events
Events or seismic sources are added with the help of the add_events() method.
Different formats are supported. The function can be called as often as
necessary to add as many events as desired. Duplicates will be automatically
discarded.
Many solvers are only able to accept a single event and thus will raise an error upon input file creation if multiple events are present.
Different ways to add one or more events are demonstrated by example:
# Add one or more QuakeML files.
gen.add_events("quake.xml")
gen.add_events(["path/to/quake1.xml", "path/to/quake2.xml"])
# Add QuakeML with the URL to a webservice.
gen.add_events("http://earthquakes.gov/quakeml?parameters=all")
# Directly add an event as a dictionary. Also a list of events.
gen.add_events({
"latitude": 45.0,
"longitude": 12.1,
"depth_in_km": 13.0,
"origin_time":
obspy.UTCDateTime(2012, 4, 12, 7, 15, 48, 500000),
# The description is optional and does not have to be given.
"description": "Some event I care about",
"m_rr": -2.11e+18,
"m_tt": -4.22e+19,
"m_pp": 4.43e+19,
"m_rt": -9.35e+18,
"m_rp": -8.38e+18,
"m_tp": -6.44e+18})
gen.add_events([{...}, {...}, ...])
# JSON also works. Either as a single JSON object or as an arrays of objects.
json_str = """
{
"latitude": 45.0,
"longitude": 12.1,
"depth_in_km": 13.0,
"origin_time": "2012-04-12T07:15:48.500000Z",
"m_rr": -2.11e+18,
"m_tt": -4.22e+19,
"m_pp": 4.43e+19,
"m_rt": -9.35e+18,
"m_rp": -8.38e+18,
"m_tp": -6.44e+18
}
"""
gen.add_events(json_str)
json_str = """
[{...}, {...}]]
"""
gen.add_events(json_str)
Adding Stations
The stations will act as the receivers during the simulation. Again, the most common formats are supported to facilitate integration into existing workflows.
# Add one or more (X)SEED files.
gen.add_stations("station1.seed")
gen.add_stations(["station2.seed", "station3_xseed.xml"])
# StationXML works just fine.
gen.add_stations("station4.xml")
gen.add_stations(["station5.ml", "station6.xml"])
# Webservices serving StationXML or (X)SEED work by
# simply providing the URL.
gen.add_stations("http://fdsn_webservice.org/...")
# There is also legacy support for coordinates
# embedded into SAC files.
gen.add_stations("station7.sac")
gen.add_stations(["station8.sac", "station9.sac"])
# Furthermore Python dictionaries are fine. The id is
# a simple string but for many purposes it should be
# NETWORK_ID.STATION_ID as defined in the SEED manual.
gen.add_stations({
"id": "BW.FURT",
"latitude": 48.162899,
"longitude": 11.2752,
"elevation_in_m": 565.0,
"local_depth_in_m": 10.0})
gen.add_stations([{...}, {...}, ...])
# JSON objects and arrays of objects.
json_str = """
{
"id": "BW.FURT",
"latitude": 48.162899,
"longitude": 11.2752,
"elevation_in_m": 565.0,
"local_depth_in_m": 10.0})
}
"""
gen.add_stations(json_str)
json_str = """
[{...}, {...}, ...]
"""
gen.add_stations(json_str)
Event and Station Filters
Events and stations can be filtered. This is useful for using the same (potentially very large) StationXML and QuakeML files for many simulations. Simply provide a different filter for each run restricting the existing dataset.
Filters are defined as positive filters, thus they describe what should be the content of the input files and not what should be neglected.
You can set and change the filters at any time during the setup process. They are applied at input file creation time.
Event Filters
Event filters are only useful for QuakeML input as they depend on the public id of an event. They are simply a list of one ore more event ids. Note that any event not having an event id will be discarded as soon as a filter is present.
gen.event_filter = ["smi:local/event_id_1", "smi:/local_event_id_2"]
# A JSON array also works.
gen.event_filter = '["smi:local/event_id_1", "smi:/local_event_id_2"]'
Station Filters
Station filters are a list of station ids. UNIX style wildcards are supported.
gen.station_filter = ["BW.FURT", "TA.A*", "TA.Y?H"]
# Again JSON arrays are just as fine.
gen.station_filter = '["BW.FURT", "TA.A*", "TA.Y?H"]'
Solver Specific Configuration
The rest of the configuration is unfortunately very solver dependent. The inputs they require are just too different to make it feasible to extract a common subset.
If needed the supported output formats of the module can be queried:
>>> gen.get_available_formats()
['ses3d_4_1', 'SPECFEM3D_CARTESIAN']
It is also possible to request the parameters needed for a specific solver. The
get_config_params() method returns two dictionaries. The first one describes
the required parameters; the keys are the parameter names and the values a
two-tuple of type and description. The second one describes the optional
parameters. The keys are once again the parameters names, the values this time
a three-tuple of default value, type, and description.
>>> required, optional = gen.get_config_params('ses3d_4_1')
>>> required.items()[0]
('mesh_max_longitude', (float, 'The maximum longitude of the mesh'))
>>> optional.items()[0]
('adjoint_forward_sampling_rate', (15, int, 'The sampling...')
Once the necessary parameters are known they can be set in a couple of
different ways. The required parameters must be set before a file can be
written, otherwise an error will be raised. If no value is given for an
optional parameter, its default value will be used. Automatic type conversion
will be performed by the write() method. If it fails an error will be
raised.
# Directly attach attributes to the config object.
gen.config.time_stepping = 5.5
# Set values from a dictionary.
gen.add_configuration({'some_value': 2,
'other_value': 2})
# From a JSON string.
gen.add_configuration('{"some_value":2, ...}')
The last step is to actually write the input files. Per default it will return a dictionary with the keys being the filenames and the values being the file contents.
>>> output = gen.write(format="ses3d_4_1")
>>> output.keys()
['stf', 'relax', 'setup', 'event_list', 'event_1', 'recfile_1']
# One can also directly write the files to a specified folder.
gen.write(format="ses3d_4_1", output_dir="solver_input_files")
Adding Support for a new Solver
Adding support for a new solver (also called a backend) is simply a matter of adding a new Python script. The input file generator main class will take care of discovering and using it.
All backends have to be stored in the wfs_input_generator/backends
subdirectory. It has to have the name write_SOLVER.py where SOLVER should
be an accurate description of the used solver.
The best way to add a new solver is to use an existing one as a template.
The file has to contain three things, the definition of the required
parameters, the definition of the optional parameters, and a write()
function.
The wfs_input_generator module will take care that all required parameters will be present and that all parameters have the correct type.
Definition of the Required Parameters
The required parameters are specified in the file in a variable called
REQUIRED_CONFIGURATION. It is a dictionary with the keys being the parameter
names and the values a two-tuple of type and description.
REQUIRED_CONFIGURATION = {
"some_parameter": (str, "This does something"),
"another_parameters": (float, "This does something else),
"one_more": (lambda x: map(float, x), "This will always be a list of floats")
}
Definition of the Optional Parameters
The optional parameters are specified in the file in a variable called
DEFAULT_CONFIGURATION. It is another dictionary. The keys are once again the
parameters names, the values this time a three-tuple of default value, type,
and description.
DEFAULT_CONFIGURATION = {
"some_required_parameter": ("default", str, "A parameter"),
...
}
The write() Function
The write() function will be called to assemble the input files. This is the
actual job of any backend.
The file has to have a call signature akin to
def write(config, events, stations):
# Logic here
...
return {
"filename_1": content_1,
"filename_2": content_2
}
and return a dictionary with the keys being the names of the files to be generated and the values being the actual contents. Unicode should work just fine.
At any point you can be sure that the contents of the three arguments are fine. You do not need to perform any type checking or test for missing parameters. The module takes care that the parameters are sanitized.
What you need to do is check things that cannot be caught by the parameter specification or something else, e.g. raise an error if more than one event is present but the solver can only deal with one event at a time and similar things.
The config Argument
The config argument is a obspy.core.AttribDict instance and will contain all
the values specified in REQUIRED_CONFIGURATION and DEFAULT_CONFIGURATION.
All parameters will be present; the wfs_input_generator module assures that
the user specified all required parameters. Also all optional parameters will
be present; values that the user did not specify will be replaced by the
default values.
The events Argument
It is a list of dictionaries. You can be sure they have the following format:
{"latitude": 28.7,
"longitude": -113.1,
"depth_in_km": 13.0,
"origin_time": obspy.UTCDateTime(2012, 4, 12, 7, 15, 48, 500000),
# Description will be either a string describing the event or `None`.
"description": "Place of event",
"m_rr": -2.11e+18,
"m_tt": -4.22e+19,
"m_pp": 4.43e+19,
"m_rt": -9.35e+18,
"m_rp": -8.38e+18,
"m_tp": -6.44e+18}
The origin_time value will be an obspy.UTCDateTime instance, the rest
ordinary floats. Again no need to check for any missing parameters. They will
all be present and have the correct type.
The stations Argument
It is a list of dictionaries. You can be sure they have the following format:
{"id": "BW.FURT",
"latitude": 48.162899,
"longitude": 11.2752,
"elevation_in_m": 565.0,
"local_depth_in_m": 0.0},
The id value will be a string and all other values will be floats.